
Algorytm naiwny jest jednym z najprostszych sposobów wyszukiwania wzorca w tekście. Jego prostota polega na tym, że porównuje wzorzec z każdą możliwą pozycją w tekście bez żadnych zaawansowanych optymalizacji. Mimo że nie jest najbardziej wydajnym rozwiązaniem (szczególnie dla dużych tekstów), jest intuicyjny i łatwy do zrozumienia.
1. Opis algorytmu naiwnego
Załóżmy, że mamy tekst T o długości n i wzorzec P o długości m, gdzie n >= m. Algorytm naiwny polega na przesuwaniu wzorca P wzdłuż tekstu T, znak po znaku, i sprawdzaniu, czy w danej pozycji wzorzec w pełni odpowiada fragmentowi tekstu.
- Rozpoczynamy od sprawdzenia, czy wzorzec pasuje do pierwszego fragmentu tekstu, zaczynającego się na pozycji 0.
- Następnie przesuwamy wzorzec o jedną pozycję i ponownie sprawdzamy dopasowanie.
- Proces powtarzamy, aż wzorzec zostanie porównany z wszystkimi możliwymi pozycjami w tekście.
2. Złożoność czasowa
Algorytm naiwny ma złożoność czasową O(n * m), gdzie:
nto długość tekstu,mto długość wzorca.
W najgorszym przypadku, dla każdego z n - m + 1 przesunięć, algorytm wykonuje porównanie wszystkich m znaków wzorca z odpowiadającym fragmentem tekstu.
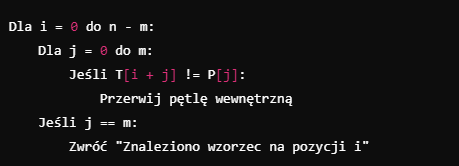
3. Pseudokod algorytmu
Poniżej znajduje się prosty pseudokod dla algorytmu naiwnego:
4. Implementacja algorytmu naiwnego w Pythonie
Poniżej znajduje się implementacja algorytmu naiwnego w języku Python.
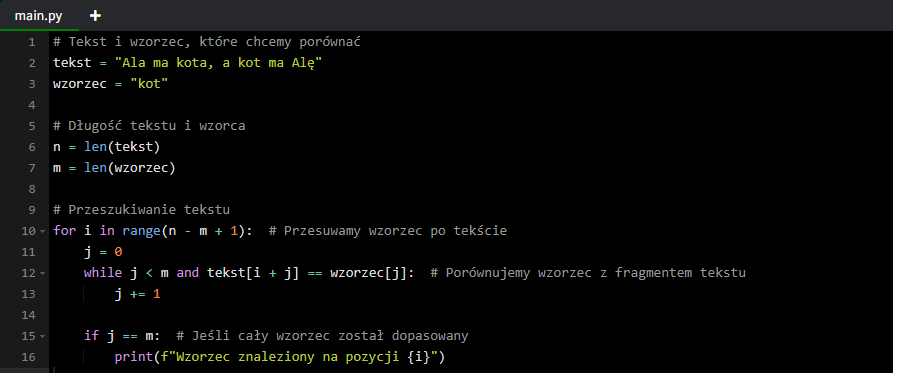
W tym przykładzie algorytm przeszukuje tekst w celu znalezienia wszystkich wystąpień słowa „kot”. W przypadku dopasowania wzorca, algorytm zwraca pozycję, od której zaczyna się wzorzec w tekście.
5. Przykład działania
Załóżmy, że mamy tekst:
"Ala ma kota, a kot ma Alę"
Oraz wzorzec:
"kot"
Algorytm zaczyna od pierwszej pozycji w tekście i porównuje fragment o długości wzorca (czyli 3 znaki) z wzorcem. Jeśli wzorzec nie pasuje, przesuwa się o jeden znak i powtarza proces, aż znajdzie dopasowanie.
W wyniku tego procesu algorytm znajdzie dopasowanie na pozycji 7 oraz 15, gdzie występuje słowo „kot”.
6. Zalety i wady algorytmu naiwnego
Zalety:
- Łatwy do implementacji.
- Nie wymaga skomplikowanej struktury danych.
- Intuicyjny do zrozumienia, co sprawia, że jest idealny do nauki podstaw wyszukiwania wzorców.
Wady:
- Wydajność: Dla dużych tekstów i długich wzorców algorytm działa wolno, ponieważ porównuje każdą możliwą pozycję w tekście, nawet jeśli część porównań można by było pominąć.
- Brak optymalizacji: Algorytm nie wykorzystuje żadnych informacji o wzorcu do optymalizacji porównań.
7. Podsumowanie
Algorytm naiwny jest podstawowym rozwiązaniem problemu wyszukiwania wzorca w tekście. Jego największą zaletą jest prostota i łatwość implementacji, jednak w przypadku dużych tekstów i wzorców staje się nieefektywny. W praktyce, bardziej zaawansowane algorytmy, takie jak KMP (Knutha-Morrisa-Pratta) czy algorytm Boyera-Moore’a, oferują lepszą wydajność dzięki wykorzystaniu dodatkowych informacji o wzorcu.
Mimo to algorytm naiwny jest doskonałym punktem wyjścia do zrozumienia problemu wyszukiwania wzorców i stanowi bazę do nauki bardziej zaawansowanych metod.
Was this helpful?
0 / 0