Czym są relacyjne bazy danych?
Relacyjne bazy danych to systemy przechowywania i organizacji danych, które opierają się na modelu relacyjnym, zaproponowanym po raz pierwszy przez Edgara F. Codd’a w 1970 roku. W tym modelu dane przechowywane są w tabelach (zwanych również relacjami), które składają się z wierszy (rekordów) i kolumn (atrybutów). Kluczową cechą tego podejścia jest możliwość łączenia danych z różnych tabel za pomocą relacji, co umożliwia efektywne i bez nadmiarowości przechowywanie złożonych informacji.
Podstawowe pojęcia
1. Tabele (Relacje)
Tabela to podstawowa struktura organizująca dane, składająca się z:
-
Kolumny (atrybuty) – definiują rodzaj przechowywanych danych (np. imię, nazwisko, wiek)
-
Wiersze (krotki) – reprezentują pojedyncze rekordy danych
-
Schemat tabeli – definicja struktury tabeli (nazwy kolumn, typy danych)
2. Klucze
-
Klucz główny (Primary Key) – unikalny identyfikator każdego wiersza w tabeli
-
Klucz obcy (Foreign Key) – odwołanie do klucza głównego w innej tabeli, tworzące relację
3. Relacje
Relacje między tabelami są podstawą modelu relacyjnego:
-
Jeden-do-jednego (1:1) – każdy rekord w tabeli A odpowiada dokładnie jednemu rekordowi w tabeli B
-
Jeden-do-wielu (1:N) – rekord w tabeli A może być powiązany z wieloma rekordami w tabeli B
-
Wiele-do-wielu (N:M) – wymaga tabeli pośredniej (łączącej)
Zasady ACID – fundament niezawodności
Relacyjne bazy danych przestrzegają zasad ACID, które gwarantują niezawodność przetwarzania transakcji:
-
Atomowość – transakcja jest wykonywana w całości lub wcale
-
Spójność – transakcja przenosi bazę danych z jednego stanu spójnego w inny stan spójny
-
Izolacja – równoległe transakcje nie wpływają na siebie nawzajem
-
Trwałość – po zatwierdzeniu transakcji jej zmiany są permanentne
Język SQL (Structured Query Language)
SQL to standardowy język do komunikacji z relacyjnymi bazami danych. Składa się z kilku głównych kategorii poleceń:
DDL (Data Definition Language)
-
CREATE– tworzenie tabel i innych obiektów -
ALTER– modyfikacja struktury -
DROP– usuwanie obiektów
DML (Data Manipulation Language)
-
SELECT– pobieranie danych -
INSERT– dodawanie nowych rekordów -
UPDATE– modyfikacja istniejących rekordów -
DELETE– usuwanie rekordów
DCL (Data Control Language)
-
GRANT– nadawanie uprawnień -
REVOKE– odbieranie uprawnień
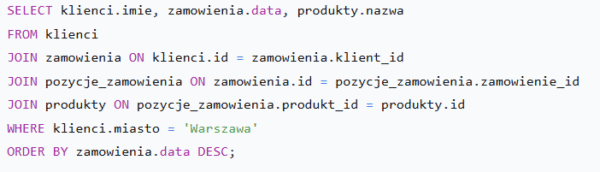
Przykładowe zapytanie SQL:
Normalizacja – eliminacja redundancji
Normalizacja to proces organizowania danych w bazie w celu minimalizacji redundancji i zależności. Główne formy normalne:
-
1NF (Pierwsza postać normalna) – każda kolumna zawiera tylko wartości atomowe, brak powtarzających się grup
-
2NF (Druga postać normalna) – spełnia 1NF i każdy niekluczowy atrybut jest w pełni zależny od całego klucza głównego
-
3NF (Trzecia postać normalna) – spełnia 2NF i żaden niekluczowy atrybut nie jest zależny od innego niekluczowego atrybutu (brak zależności przechodnich)
Zalety relacyjnych baz danych
-
Strukturalność – ścisła organizacja danych według predefiniowanego schematu
-
Spójność – dzięki zasadom ACID i normalizacji
-
Bezpieczeństwo – zaawansowane systemy kontroli dostępu i uprawnień
-
Elastyczność – możliwość tworzenia złożonych zapytań i raportów
-
Standaryzacja – powszechnie przyjęty standard SQL
-
Integralność referencyjna – automatyczne egzekwowanie relacji między tabelami
Ograniczenia
-
Sztywność schematu – zmiana struktury może być skomplikowana
-
Skalowalność w poziomie – tradycyjne rozwiązania RDBMS mają ograniczenia w skalowaniu horyzontalnym
-
Wydajność przy dużych wolumenach – niektóre operacje mogą być wolniejsze niż w bazach NoSQL
-
Złożoność – dla prostych przypadków użycia może być to rozwiązanie nadmiarowe
Popularne systemy DBMS
-
Oracle Database – zaawansowane rozwiązanie korporacyjne
-
MySQL/MariaDB – popularne otwartoźródłowe systemy
-
Microsoft SQL Server – rozwiązanie Microsoft dla środowisk Windows
-
PostgreSQL – zaawansowany otwartoźródłowy system z rozbudowanymi funkcjami
-
SQLite – lekka, samodzielna baza danych bez serwera
Przyszłość relacyjnych baz danych
Współczesne trendy w rozwoju relacyjnych baz danych obejmują:
-
Hybrydowe modele – łączenie zalet SQL i NoSQL (np. PostgreSQL z obsługą JSON)
-
Chmurowe wdrożenia – usługi DBaaS (Database as a Service)
-
Zwiększona wydajność – nowe algorytmy i struktury danych
-
Integracja z AI/ML – wbudowane funkcje analityczne i predykcyjne
Podsumowanie
Relacyjne bazy danych pozostają fundamentalną technologią w dziedzinie zarządzania danymi od ponad czterech dekad. Pomimo pojawienia się alternatywnych rozwiązań NoSQL, systemy RDBMS wciąż dominują w aplikacjach wymagających wysokiej spójności danych, złożonych transakcji i rygorystycznej struktury. Zrozumienie ich zasad działania, możliwości i ograniczeń jest niezbędne dla każdego profesjonalisty zajmującego się przechowywaniem i przetwarzaniem danych.
Kluczem do efektywnego wykorzystania relacyjnych baz danych jest odpowiednie projektowanie schematu, stosowanie zasad normalizacji oraz umiejętne wykorzystanie języka SQL do wydobywania i manipulowania danymi w sposób optymalny i bezpieczny.
Was this helpful?
0 / 0